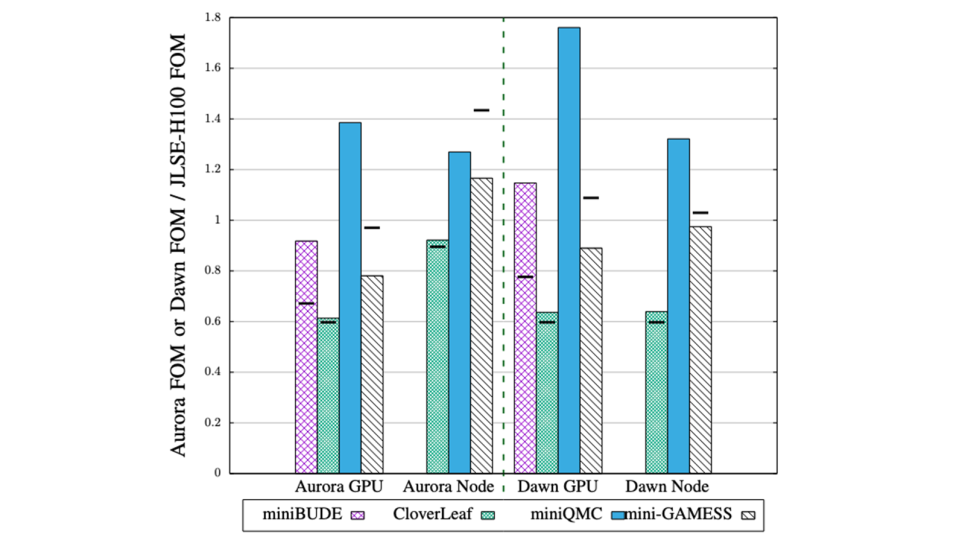
Figures of merit for Aurora and Dawn relative to JLSE-H100. The black bars show the expected relative performance based on microbenchmarking results and theoretical peaks. (Image: Applencourt et al., SC ’24 Workshops 2025)
Figures of merit for Aurora and Dawn relative to JLSE-H100. The black bars show the expected relative performance based on microbenchmarking results and theoretical peaks. (Image: Applencourt et al., SC ’24 Workshops 2025)
Figures of merit for Aurora and Dawn relative to JLSE-H100. The black bars show the expected relative performance based on microbenchmarking results and theoretical peaks. (Image: Applencourt et al., SC ’24 Workshops 2025)
This project provides a comprehensive performance evaluation of Intel’s Ponte Vecchio GPUs with the supercomputers Aurora and Dawn, using microbenchmarks, mini-apps, and real scientific applications. The results show that the Intel GPU delivers competitive or superior performance compared to other tested GPUs, offering valuable insights for developers targeting these new architectures.
High-performance computing increasingly relies on GPUs to accelerate complex scientific simulations, yet Intel’s new Data Center GPU Max 1550 (Ponte Vecchio orPVC) lacks extensive benchmarking data to guide developers. Unlike the widely studied NVIDIA and AMD GPUs, PVC’s novel architecture and deployment in the Aurora and Dawn supercomputers present uncertainty about its achievable performance and optimization strategies for application developers.
The researchers conducted detailed microbenchmarking on single GPUs and nodes of Dawn and Aurora systems using high-level programming models (OpenMP, SYCL, MPI) to measure key performance metrics such as floating-point throughput, memory bandwidth, communication latency, and matrix multiplication performance. They evaluated four mini-applications and two full applications on PVC, comparing results with NVIDIA H100 and AMD MI250 GPUs to contextualize performance differences and identify architectural bottlenecks.
Microbenchmarking revealed PVC’s compute and memory performance is competitive with or exceeds that of NVIDIA H100 and AMD MI250 GPUs, with mini-apps on a single PVC achieving 0.6–1.8x H100 and 0.8–7.5x MI250 performance. Real-world applications like OpenMC and CRK-HACC ran efficiently on PVC-based nodes, with Aurora’s 6x PVC node outperforming the NVIDIA H100 node by 1.7x in OpenMC. The study also highlighted node-level design impacts on performance and showed the robustness of PVC’s software stack across multiple programming models. The team's work was recognized with the Best Paper award at the Performance Modeling, Benchmarking, and Simulation of High Performance Computer Systems (PMBS24) Workshop at SC24.
This comprehensive performance characterization provides critical reference data and insights for developers targeting PVC-based supercomputers, accelerating application optimization and adoption of Intel GPUs in high-performance computing. By demonstrating competitive performance and identifying system-level bottlenecks, this work lays the groundwork for future benchmarking and application development on emerging Intel GPU architectures, supporting scientific advancements across computational domains.
Publications
Applencourt, T., A. Sadawarte, S. Muralidharan, C. Bertoni, J. Kwack, Y. Luo, E. Rangel, J. Tramm, Y. Ghadar, A. Tamerus, C. Edsall, and T. Deakin. “Ponte Vecchio Across the Atlantic: Single-Node Benchmarking of Two Intel GPU Systems,” Proceedings of the SC ’24 Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis (February 2025), IEEE.
https://doi.org/10.1109/SCW63240.2024.00184