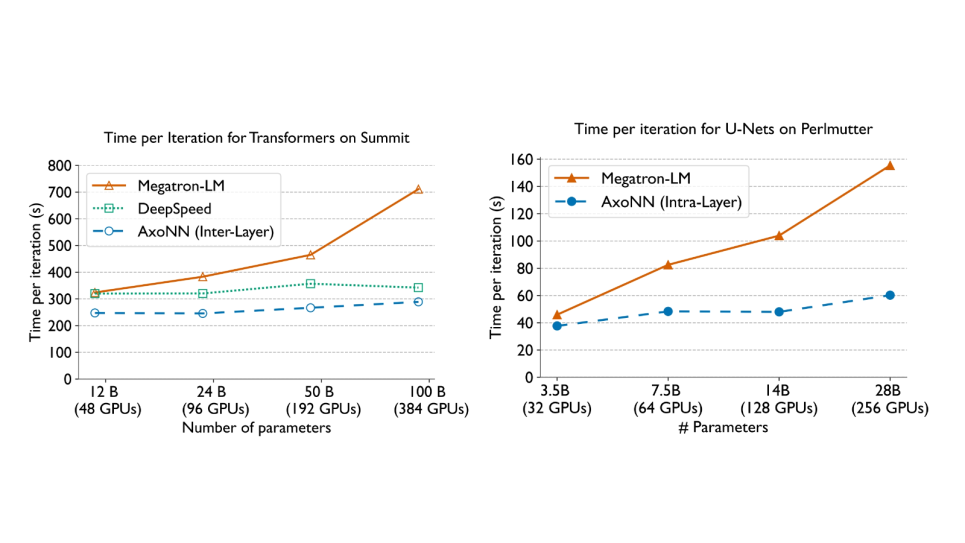
Comparing the weak scaling performance of AxoNN’s i. (left) inter-layer parallelism with other frameworks on Summit (V100s) using GPT-style transformers [17, 85], and ii. (right) intra-layer parallelism with other frameworks on Perlmutter (A100s) using UNets [55].